The foundation
To set the scene and put a plot in place for the big play, we needed a stage that could support a variety of data artists and props to power up the data. Given Google’s support and focus in the insurance market, we realised the benefits of going hand in hand with the cloud provider from an early stage.
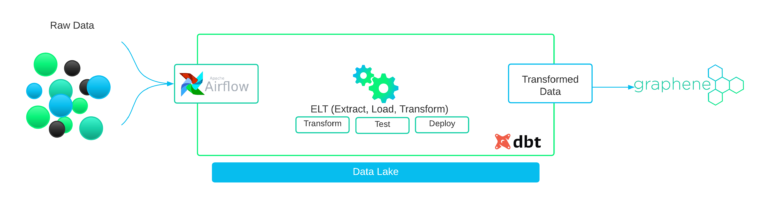
In the image above, we can see that data is the lifeline of Graphene, and that makes the availability of data a key element in the system. As we progressed into bringing ideas into reality, Google Cloud provided us with a mature big-data ecosystem to deliver the most value out of the data and its applications.
As we set up the initial pieces of the infrastructure, another challenge was to find an efficient way of structuring data to answer those key business questions. Building a data warehouse was the first instinct. When we analysed the fast-changing technical ecosystem within the insurance market, it became clear that a data lake was the optimal path. It allowed us to ingest data of various formats from a variety of sources, giving us the flexibility to evolve rapidly with the industry’s evolving data landscape.
The ingestion part
Now that the foundation is in place, we moved forward into designing the ingestion side of things. As we see insurance marketing catch up to the digital norms of the world, data ingestion is still a bit challenging at times. We attacked the problem from many different angles and found our way to a reliable tool that could support future growth.
Airflow is a well-known player in building data pipelines. Its modular architecture provides a seamless way of communicating between data pipelines and orchestrating data flows elegantly. As it’s open-source, there is a huge community always answering the unknowns and helping everyone out. As a tool, Airflow didn’t just give us a platform to orchestrate data extraction pipelines but also a framework to work with for consuming and processing data from a myriad of different data sources.
Processing the hell out of data
When you are a small team, sometimes it’s easy to slip through the guidelines and end up with a lot of mess to clean in the end. As the data arrives in our data lake, we need to get it ready to answer some critical business questions.
Raw data is useful at times and is useful to perform exploratory data analysis to form initial hypotheses and valid assumptions. However, when building things to scale with an operating model, quick hacks are never helpful. In this moment of data mess, DBT came in to show us the best way forward. As they say, DBT helps data teams work as software engineers to ship trusted data faster.
DBT enabled us to manage our data models as code which opened doors for collaborative innovation, and at the end of the day, knowledge is not concentrated to only a few people in the team as we grow.
Developing at pace without losing quality
With tons of options available, from SaaS platforms to technical frameworks for one to pick from, it gets hard to focus on delivering value sometimes. Every start-up out there faces these challenges. There are start-ups that offer products to other start-ups and then there are big companies; finding the right balance is always challenging. As a business-facing product, we decided not to reinvent the wheel and engineer things from scratch. Looking out into the market and seeing what other high-impact start-ups are using and evaluating options with a lens of “value over effort” metric, we added some smart tools to our tech stack.
That said, there is a considerable element of how the team operates in delivering the value as well. Taking inspiration from the development cycles at Netflix, we designed a flexible infrastructure within Google Cloud that incubates our rapid development of tech and data analytics. We use the full-cycle development framework to build new features.
From the term full-cycle development I mean, a developer owns everything from local development to production deployment. Rapid feature development, end to end ownership and instant issue resolution are just a few top benefits of this framework. The framework might not look the same as it is today and the art is in adapting to the changing pace of development and the demands of the start-up as Carbon grows.