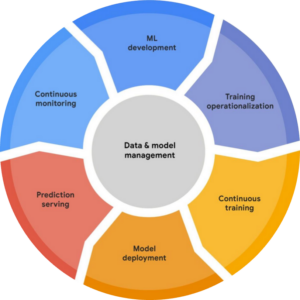
Vertex AI is our gateway to MLOps, allowing us to streamline machine learning projects from the stage of exploratory data analysis to sharing model predictions with other apps in the Graphene ecosystem.
Okay, there is a stage to perform now but what about the performance? How is this helping with Carbon category classification?
Vertex AI helped us to develop quick and dirty proof of concepts on their Managed Jupyter notebooks (a place for data scientists to write some code and evaluate their hypothesis). We start with claims data as it is in a small quantity. Our claims team prepared a list of Carbon categories for a given claim description. We used that to train our ML model and provide predictions for new claim descriptions.
Let’s dive into this process a little deeper. In the field of Natural Language Processing where understanding the semantics of the text is important, generating high quality text embeddings is critical. In simple terms, an embedding is a numeric representation of a text. However, how will that embedding be generated for a given text which is semantically accurate? To solve this problem, we took the Transfer Learning route. We used Google’s Universal Sentence Encoder (trained on billions of words on the internet) to generate semantically accurate embeddings for Claim descriptions.
Having high quality embeddings, we evaluated a few classification models and decided to stick with a simple k-nearest neighbour classifier which allowed us to classify Claim categories. As a result, “leakage in the roof”, for example, is classified as “Water Damage”.
We have put a data pipeline in place to automatically classify new claim descriptions as the data arrives in our data warehouse, this is done using our trained KNN model sitting behind Vertex AI-managed prediction endpoints. On the other side, our claims team flags any incorrect matches, and we use the active feedback to improve the model. Scheduled notebook executions on Vertex AI made this process flawless.
Vertex AI to classify claims, is that it?
Claims classification was our first project on the Vertex AI enabled ML infrastructure. This has now made it easy to train risk category classification models and opened doors to new machine learning ideas.
Our philosophy of cross-team collaboration and full cycle development is baked into our MLOps as well. Allowing anyone in the team to take on machine learning projects, share findings and deploy into production.
Lastly, machine learning is going to help our team to work faster, smarter and discover the unseen from our rapidly growing data warehouse.